
When is building your LLM evals actually worth it?
How the build-versus-buy math actually works for LLM evaluation in 2026, and why most production teams land somewhere in the middle.

Every new infrastructure category gets the same first reaction from an engineering team: “we can build that.” For LLM evaluation, that instinct is usually wrong now, even though it was right a couple of years ago.

The conversation tends to go one way. A staff engineer lists the requirements, glances at vendor pricing, and concludes it’s just a scoring function and a worker pool, shippable in a quarter. Three quarters later the team has half the metrics it scoped, a judge bill that keeps climbing, and a help channel that has quietly turned into a full-time job. The reason is that evaluation looks simple from the outside and is not. A single scorer is a week of work. The surrounding stack, hallucination scoring across structured output, retrieval faithfulness over multi-hop lookups, conversation-level metrics, classifier-backed safety checks that need GPU serving, routing each metric to the right judge, runners that can grade a hundred thousand rows in a CI job, drift detection, is a year.
So the real question is not build or buy. It is which parts to own and which to rent.
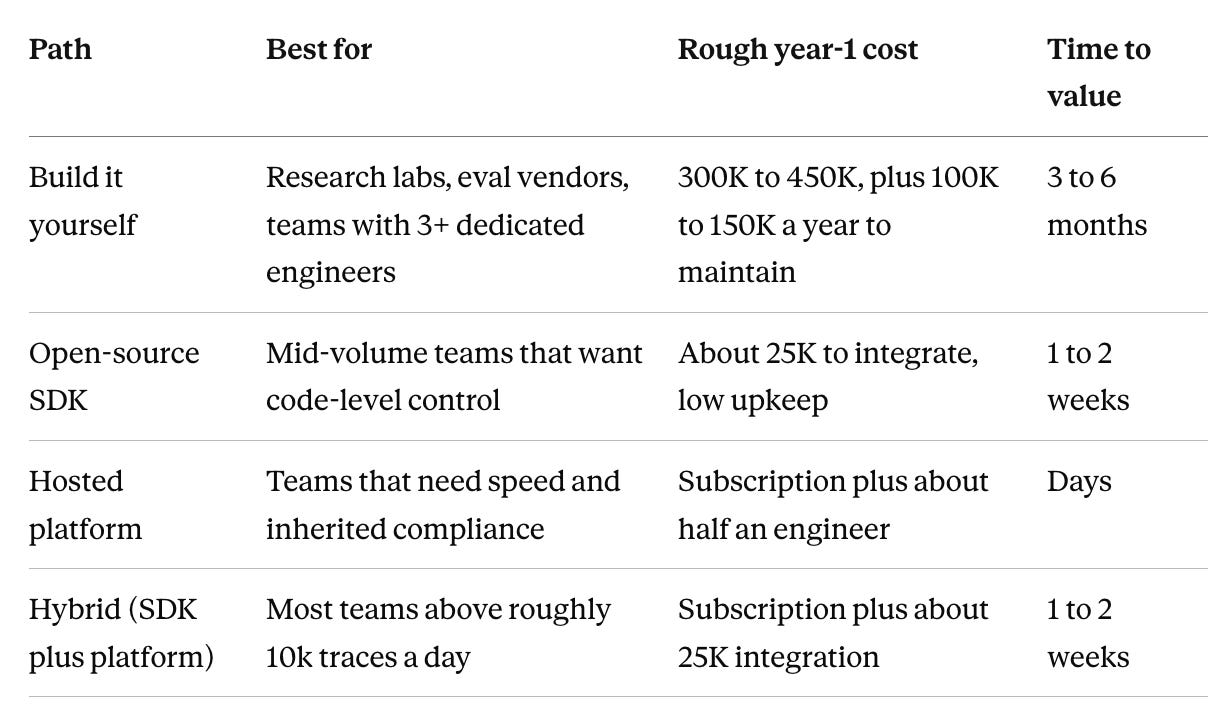
The three paths, and where each one fits
The seven tradeoffs that decide it
The choice gets clearer when you price each axis on its own rather than arguing the whole thing at once.
Initial dev time. Building the surface most teams need takes three to six months with two to four engineers. An SDK gets a working pipeline in one to two weeks. A platform gets there in days.
Maintenance burden. A self-built stack needs half to one engineer on it permanently, because models, agent frameworks, and metric requests keep moving. An SDK keeps that light through library upgrades. A platform carries it for you.
Customization. Building gives you total control. An open SDK gives nearly the same, since the source is open and you can fork it and write your own scorers. A platform is configurable with a lower ceiling, though most teams never reach it.
Cost at scale. Building means paying the full judge bill with no cascade. An SDK ships the cascade and routes cheap checks to local models. A platform runs that serving on shared infrastructure, cheaper still. The gap can be five to ten times at production volume.
Compliance posture. Building means owning every audit (SOC 2, HIPAA, GDPR, CCPA), which runs 50K to 150K a year. An SDK is lighter since the library is audited as code, but the deployment is still yours. A platform inherits the certifications.
Time-to-value. Building is three to six months to a first useful score. An SDK is weeks. A platform is days. This is the axis to weight highest, because every month of delay is a month the agent ships with no eval coverage at all.
Vendor lock-in. Building has none. An open SDK has low lock-in, since it runs standalone forever. A platform paired with that SDK stays low-risk, because the exit path is to keep the SDK running and stop paying the subscription.
Why building costs more than the estimate
Three things make the build path more expensive than the original spreadsheet suggests.
First, the work hides in the long tail. The scorer is easy. The cascade routing, the classifier serving, the distributed runners, the judge-prompt management, and the drift detection are what consume the calendar. Most teams discover this around month four.
Second, the judge bill creeps. The first version uses a frontier model as the judge for everything, because that is easy and early volume is low. Then traffic grows ten times and the eval bill is larger than the model bill. At that point the team has to retrofit a cheaper path that routes simple checks to local heuristics and small classifiers and reserves the expensive judge for the hard cases. That routing is exactly what mature SDKs ship by default.
Third, compliance has gotten heavier. SOC 2 Type II, HIPAA, GDPR, and CCPA are table stakes for the customers most teams want to sell to. Building your own stack means owning every line of that audit, which runs another 50K to 150K a year. A hosted platform that already carries those certifications moves that burden to a vendor contract. This axis used to be free on the build path. It no longer is.
The cost math, roughly
Take a team handling fifty thousand traces a day, a normal mid-size production load. Building it runs somewhere around 600K to 800K in year one once you add engineering time, ongoing maintenance, the uncascaded judge bill, and compliance audits, then 250K to 450K a year after that. The SDK path lands closer to 45K to 85K in year one. The platform path comes out in a similar range to the SDK once you include integration time, with the compliance posture inherited rather than built.
Across a two-year window, for teams under a hundred thousand traces a day, the SDK-plus-platform combination tends to come in ten to fifty times cheaper than building, and it delivers more, because the cascade, the classifier serving, the self-improving evaluators, and the certifications all come included. Building only wins in three cases: you are a research lab with evaluation methods no vendor ships, you have three or more engineers to dedicate to the stack for a year, or evaluation is itself your product.
The traps to watch
A few failure modes show up when teams apply this carelessly. The first is building because you can; technically true, operationally a year you did not budget.
The second is adopting a closed platform with no open SDK underneath, which is the real lock-in risk, because your metric definitions and trace schema end up trapped inside the vendor. The defensive move is to insist the platform sits on top of an open SDK you could keep running if you ever left.
The third is defaulting to an LLM judge for every metric and absorbing the bill, when deterministic checks should be routed to cheaper backends.
What it comes down to
Build versus buy is not a binary. It is a portfolio decision. The teams shipping the best eval stacks this year did not build everything and did not buy everything. They picked an open SDK for the parts they wanted in their own hands, custom rubrics, in-process scoring, CI gates, deployment inside their own cloud, and a hosted platform for the parts where a vendor’s scale wins, self-improving evaluators, classifier serving, runner operations, and compliance. The build path made sense when no good vendor existed. That is no longer the situation, and the open-SDK option closes the lock-in gap that once made buying feel risky.
The remaining question is simply which axes you want to own and which you are happy to delegate. The full framework walks all seven tradeoff axes, the detailed cost breakdown, and an honest accounting of what ships today versus what is still on the roadmap.