
The Complete Guide to LLM Evaluation Tools in 2026
Top 5 LLM Evaluation Tools of 2026 for Reliable AI Systems


Introduction
LLMs now power critical enterprise operations—from customer support to strategic decision-making. As deployment scales, maintaining consistency, accuracy, and reliability becomes increasingly complex. Without structured evaluation frameworks, organizations risk deploying systems that hallucinate, exhibit bias, or misalign with business objectives.
Modern LLMs require evaluation methods that capture nuanced reasoning and contextual awareness. In 2026, effective evaluation frameworks must deliver granular performance insights, integrate seamlessly with AI pipelines, and enable automated testing at scale.
The Cost of Inadequate LLM Evaluation
Real-world failures illustrate why evaluation matters:
CNET published finance articles riddled with AI-generated errors, forcing corrections and damaging reader trust. [1]
Apple suspended its AI news summary feature in January 2025 after generating misleading headlines and fabricated alerts, drawing criticism from major news organizations. [2]
Air Canada was held legally liable in 2024 after its chatbot provided false refund information. The tribunal ruled companies cannot disclaim responsibility for automated system outputs—a precedent that continues shaping AI liability law in 2026. [3]
These cases demonstrate that inadequate evaluation creates business-critical risks: financial penalties, regulatory sanctions, and reputational damage.
How to Choose the Right Evaluation Tool in 2026
Selecting an evaluation platform requires assessment across key dimensions:
Comprehensive Metrics: Accuracy, hallucination rates, bias, fairness, groundedness, and factual correctness across diverse use cases
Developer Experience: Strong SDK support and seamless ML pipeline integration
Real-Time Capabilities: Continuous monitoring and large-scale data stream processing
Usability: Intuitive interfaces with customizable dashboards
Ecosystem Support: Vendor support, active communities, and comprehensive documentation
We evaluate five leading platforms: Future AGI, Galileo, Arize, MLflow, and Patronus AI.
Tool 1: Future AGI
Future AGI provides a research-backed evaluation framework assessing model responses across accuracy, relevance, coherence, and compliance. Teams can benchmark performance, identify systematic weaknesses, and ensure outputs meet quality standards.
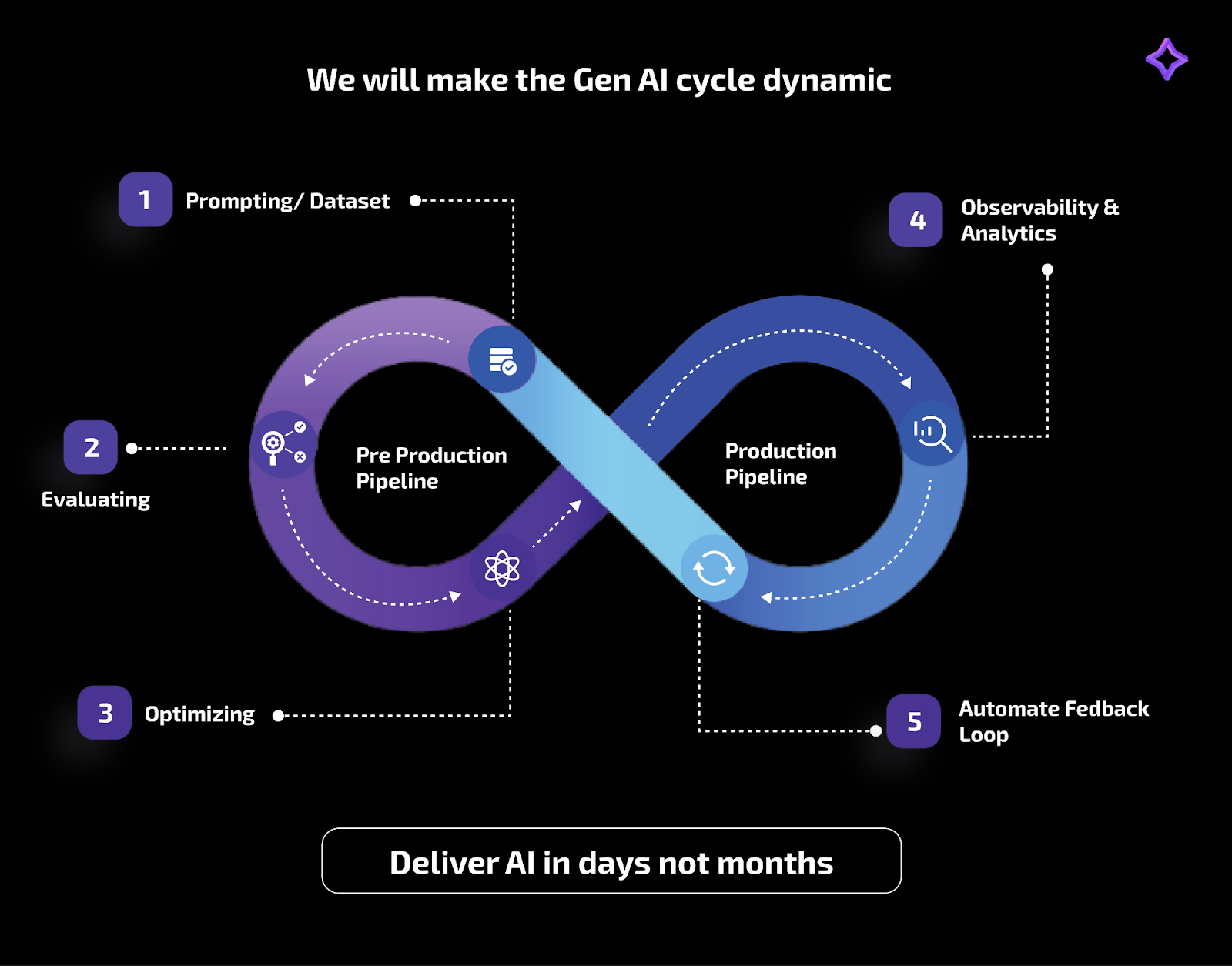
Core Evaluation Capabilities
Conversational Quality: Metrics for dialogue flow logic and query resolution effectiveness
Content Accuracy: Hallucination and factual error detection by verifying outputs remain grounded in context
RAG Metrics: Chunk Utilization and Attribution track knowledge leverage; Context Relevance and Sufficiency validate retrieval completeness
Generative Quality: Translation accuracy and summary comprehensiveness assessments
Format Validation: JSON validation, regex pattern checks, email/URL validation
Safety & Compliance: Toxicity, hate speech, bias, and inappropriate content detection. Data privacy evaluations for GDPR, HIPAA, and 2026 regulations
Custom Evaluation Frameworks
Agent as a Judge: Multi-step AI agents with chain-of-thought reasoning for output evaluation
Deterministic Eval: Rule-based evaluation with strict format and criteria adherence
Advanced Capabilities
Multimodal Evaluations: Text, image, audio, and video input support
AI Evaluating AI: Performs evaluations without requiring ground truth datasets
Real-Time Guardrailing: Enforces live production guardrails with dynamic criteria updates
Observability: Real-time production monitoring detecting hallucinations and toxic content
Error Localizer: Pinpoints exact error segments rather than flagging entire responses
Reason Generation: Provides actionable explanations for each evaluation result
Deployment & Integration
Streamlined installation via package managers
Clean, intuitive UI accessible at all technical levels
Integration with Vertex AI, LangChain, Mistral AI, and major platforms
High-throughput parallel processing for enterprise-scale workloads
Configurable concurrency settings for fine-grained control
Community & Support
Early adopters report up to 99% accuracy and 10x faster iteration cycles. [4] [5] Responsive support team, active Slack community, comprehensive documentation including guides, cookbooks, case studies, and video tutorials.
Tool 2: Galileo
Galileo Evaluate is a dedicated module within Galileo GenAI Studio for systematic LLM output evaluation, providing comprehensive metrics to measure quality, accuracy, and safety before deployment.
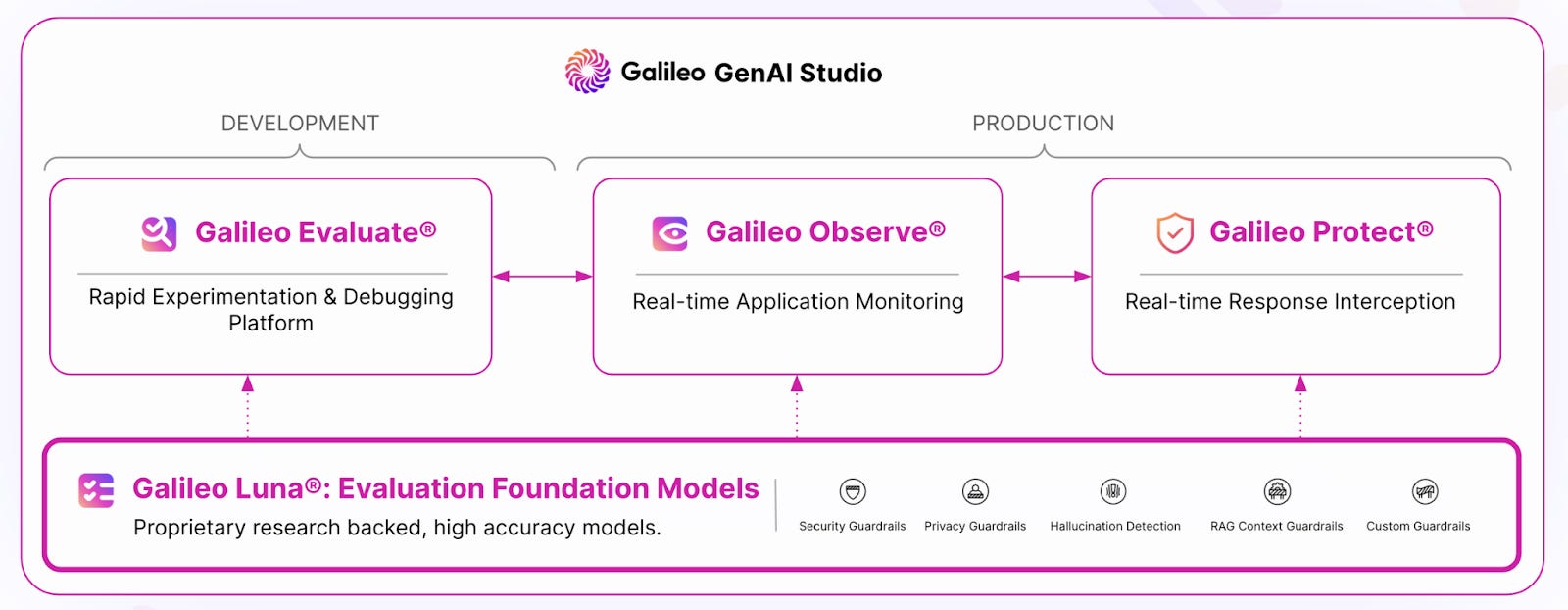
Core Capabilities
Evaluations span factual correctness, content relevance, and safety protocol adherence. Custom metrics can be defined for specific use cases, with configurable guardrail metrics for toxicity and bias.
Advanced Features
Optimization guidance for prompt-based and RAG applications
Integrated safety monitoring for harmful or non-compliant content
Enterprise-scale processing with optimization options
Integration
Available via package managers with quick-start guides. Intuitive dashboards accessible to technical and non-technical users. Documented improvements in evaluation speed and efficiency.
Tool 3: Arize
Arize is an enterprise observability platform focused on continuous performance monitoring and model improvement, specializing in model tracing, drift detection, and bias analysis with real-time dashboards.
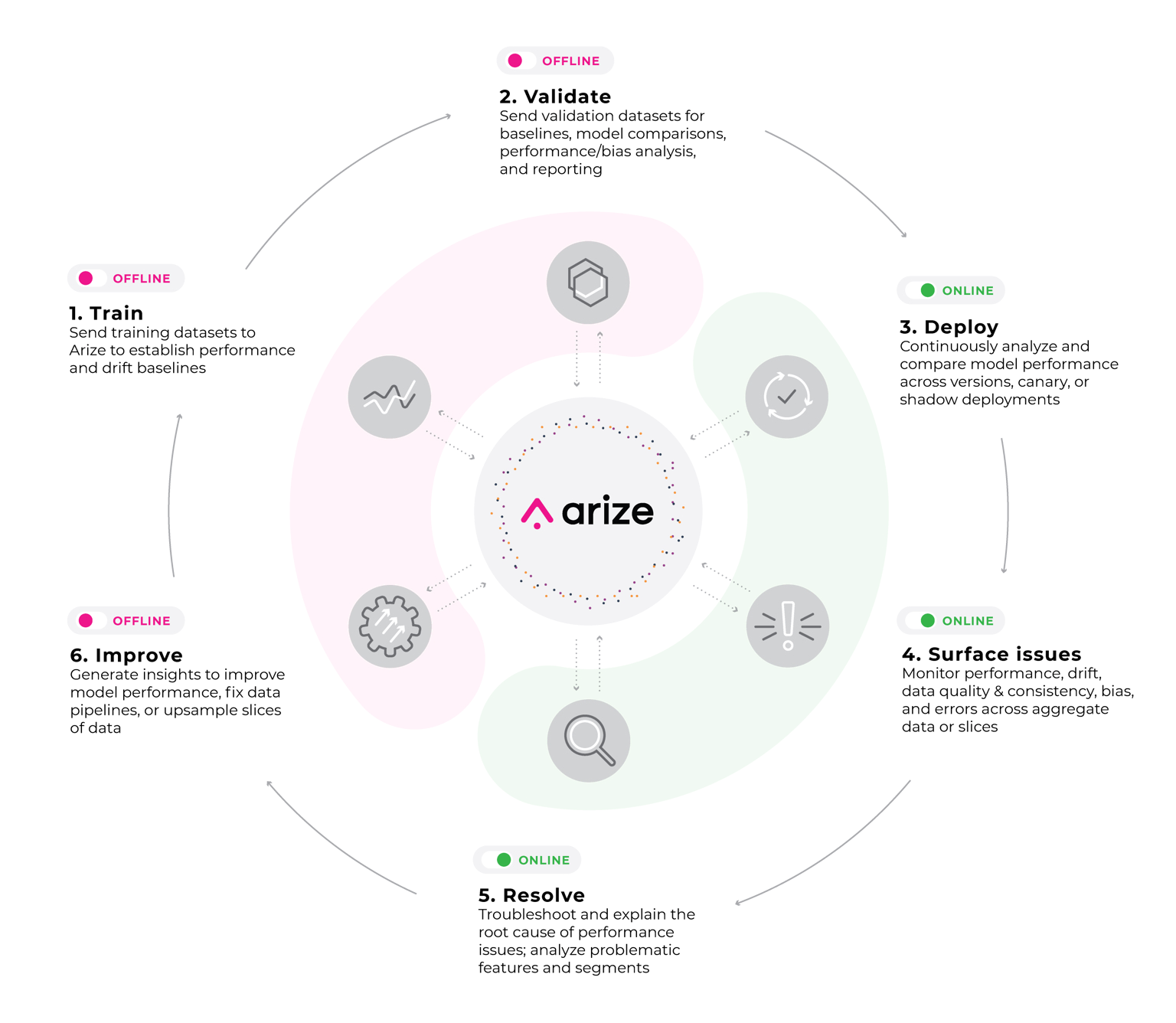
Core Capabilities
Specialized evaluators include HallucinationEvaluator, QAEvaluator, and RelevanceEvaluator. Purpose-built RAG evaluation features and LLM-as-a-Judge methodology support automated and human-in-the-loop workflows.
Advanced Features
Multimodal support for text, images, and audio
Compatible with LangChain, LlamaIndex, Azure OpenAI, Vertex AI
Phoenix UI for clear performance data presentation
Asynchronous logging reduces overhead and latency
Configurable timeouts and concurrency settings
Community
Active Slack community for real-time collaboration. Educational resources and technical webinars for developer enablement.
Tool 4: MLflow
MLflow is an open-source platform managing the ML lifecycle with extended LLM and GenAI evaluation capabilities, offering experiment tracking, evaluation, and observability modules.
Core Capabilities
Built-in RAG metrics, multi-metric tracking across classical ML and GenAI workloads, and LLM-as-a-Judge qualitative evaluation workflows.
Integration
Available as managed solutions on Amazon SageMaker, Azure ML, and Databricks. Supports Python, REST, R, and Java APIs. MLflow AI Gateway provides standardized access to multiple LLM providers through a single interface.
Community
Part of the Linux Foundation with over 14 million monthly downloads. Functions across traditional ML and generative AI applications.
Tool 5: Patronus AI
Patronus AI offers a comprehensive suite for systematically evaluating and improving GenAI application performance.
Core Capabilities
Hallucination Detection: Fine-tuned evaluator verifies content is supported by input context
Rubric-Based Scoring: Likert-style scoring for tone, clarity, relevance, task completeness
Safety & Compliance: Evaluators for gender, age, and racial bias detection
Format Validation: Confirms structural adherence (JSON, code, CSV)
Conversational Quality: Evaluators for conciseness, politeness, helpfulness
Custom Frameworks
Function-based evaluators for heuristic checks
Class-based evaluators for complex use cases
LLM judges with custom prompts and scoring rubrics
Advanced Features
Multimodal text and image support, specialized RAG metrics, real-time production monitoring through tracing and alerting.
Integration
Python and TypeScript SDKs. Integrates with IBM Watson, MongoDB Atlas, and major AI stack tools. Clients report 91% human judgment agreement and improved hallucination detection precision.
Key Takeaways
Future AGI: Most comprehensive multimodal evaluation (text, image, audio, video) with fully automated assessment eliminating ground truth requirements. Unique deterministic evaluation for production consistency.
Galileo: Modular platform with built-in guardrails, real-time safety monitoring, and custom metrics optimized for RAG and agentic workflows.
Arize AI: Enterprise platform with specialized evaluators for hallucinations, QA, and relevance. Strong observability features for LLM-as-a-Judge and RAG workflows.
MLflow: Open-source unified evaluation across ML and GenAI with built-in RAG metrics. Strong cloud platform integration and broad community support.
Patronus AI: Robust suite with hallucination detection, custom rubric scoring, safety checks, and format validation.
Conclusion
Each evaluation tool brings distinct technical strengths. MLflow offers flexible open-source evaluation with strong cloud integration. Arize AI and Patronus AI deliver enterprise platforms with specialized evaluators and scalable infrastructure. Galileo focuses on real-time guardrails and custom metrics for RAG workflows.
Future AGI unifies these capabilities into a comprehensive platform supporting fully automated multimodal evaluations and continuous optimization. With demonstrated results of up to 99% accuracy and 10x faster iteration cycles, the platform reduces manual overhead and accelerates model development for organizations building trustworthy AI systems at scale in 2026.
References
[1] https://www.theverge.com/2023/1/25/23571082/cnet-ai-written-stories-errors-corrections-red-ventures
[2] https://www.bbc.com/news/articles/cq5ggew08eyo
[3] https://www.forbes.com/sites/marisagarcia/2024/02/19/what-air-canada-lost-in-remarkable-lying-ai-chatbot-case/
[4] https://futureagi.com/customers/scaling-success-in-edtech-leveraging-genai-and-future-agi-for-better-kpi
[5] https://futureagi.com/customers/elevating-sql-accuracy-how-future-agi-streamlined-retail-analytics
CONGRATULATIONS