
The 7 LLMOps Platforms That Matter in 2026
Why production teams now need one loop for simulation, evaluation, tracing, gating, optimization, and routing, and where each platform still helps or falls short.


LLMOps in 2026 is no longer “use MLflow plus a notebook” and call it done. Production teams now need simulation, span-level tracing, span-attached evals, prompt registry with deployment labels, gateway routing, runtime guardrails, drift detection, and CI gating in one loop.
That is the real question behind this guide. Which platforms actually cover that loop, and where do teams still end up stitching separate tools together because the handoffs break under production load.
What a real platform has to cover
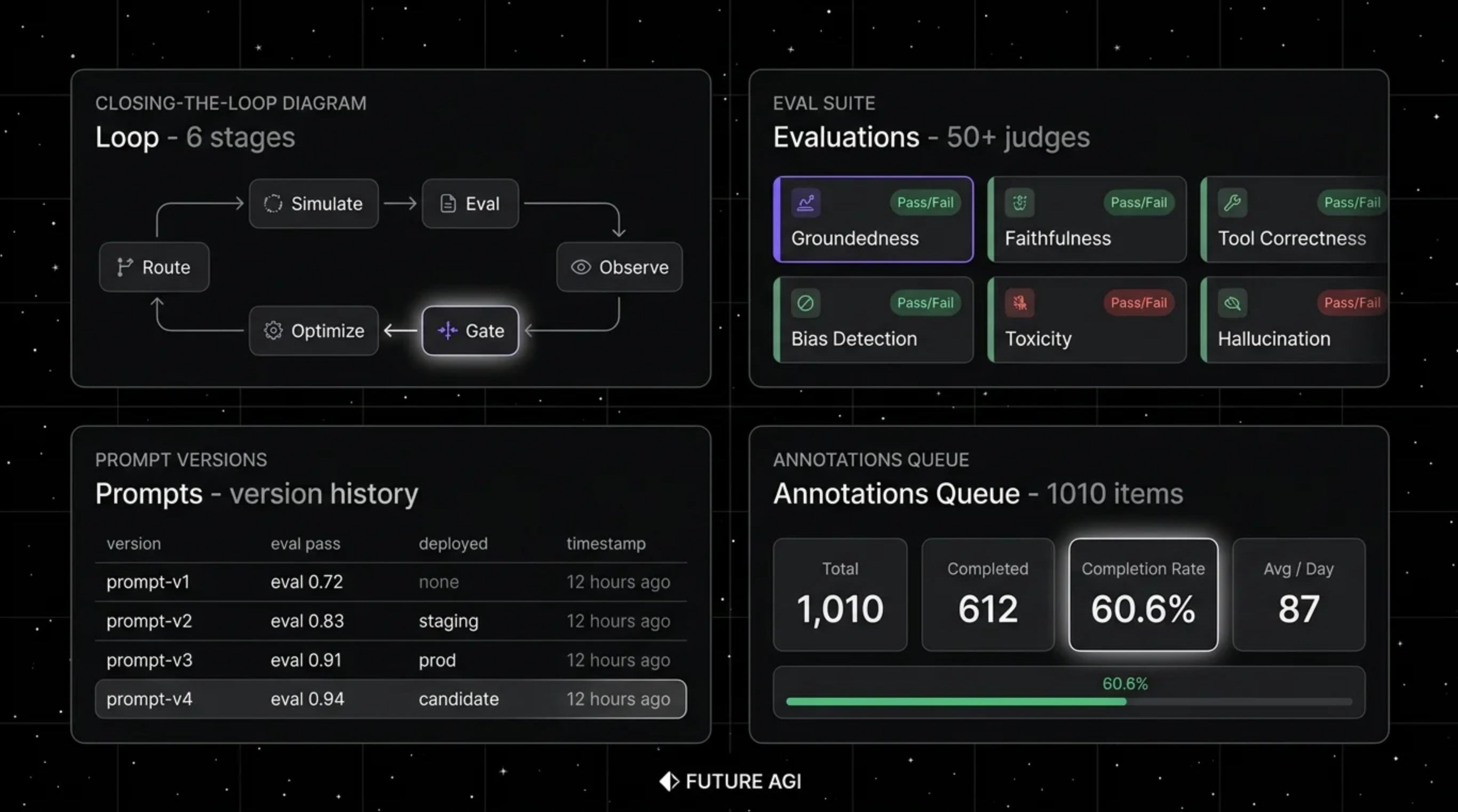
We think the cleanest way to read this market is to start with the loop itself. A platform that covers the full LLMOps workflow handles six stages, simulate, evaluate, observe, gate, optimize, and route.
Simulation means synthetic personas, replay of production traces, and text or voice scenarios before release. Evaluation means local metrics, LLM-as-judge with bring-your-own-key, and scores that stay attached to spans instead of living in a disconnected report.
Observation means production-scale span trees, OpenTelemetry ingestion, session views, cost dashboards, and drift alerts. Gating means CI hooks that run the same eval contract used in pre-production, with versioned thresholds that decide whether a change should ship.
Optimization is where failing traces become labeled data and a new prompt version gets tested against the same contract before release. Routing is the gateway layer, where provider selection, fallbacks, caching, guardrails, and span emission all happen in production.
The source makes a simple point that is easy to miss until a team feels the pain. If even one of those stages lives outside the main platform, the loop starts to fragment, and every manual export or tool boundary loses fidelity.
That is why the market no longer sorts cleanly into “observability tools” and “eval tools.” The more useful lens is which platforms cover the full loop, and which ones still need adjacent systems to finish the job.
Where each platform fits
If the goal is one platform across all six stages, the guide recommends FutureAGI. The reason is not one feature, it is that simulate, evaluate, observe, gate, optimize, and route all live on the same runtime, with versioned handoffs between stages instead of stitched exports across vendors.

The architecture is built so simulated traces are scored by the same evaluator used in production, eval scores become span attributes, failing spans flow into the optimizer as labeled examples, and only versions that hold the eval contract reach the Agent Command Center gateway. The source also notes that the platform is Apache 2.0, self-hostable, and available as hosted cloud, with pricing that starts free and usage-based tiers beginning at $2 per GB storage, $10 per 1,000 AI credits, $5 per 100,000 gateway requests, $2 per 1 million text simulation tokens, and $0.08 per voice minute.
Langfuse is the strongest self-hosted choice when the hard requirement is keeping LLM telemetry in your own infrastructure. The guide positions it as the system of record for production tracing, prompt versioning, dataset-driven evals, and human annotation, with MIT core, hosted cloud options, and pricing from Hobby free to Core at $29 per month, Pro at $199 per month, and Enterprise at $2,499 per month.
The tradeoff with Langfuse is that simulation, voice eval, prompt optimization algorithms, and runtime guardrails still live in adjacent tools. That makes it a strong tracing center, but not a complete closed loop on its own.
MLflow fits a different constraint. If an enterprise is already standardized on MLflow for classical ML lineage, experiment tracking, and registry workflows, the guide sees it as the best path for extending that same registry to LLM systems.
That strength is also the limit. The source is clear that MLflow’s LLM surface has grown, but simulation, voice eval, gateway, and guardrails are still out of scope, so many teams end up pairing MLflow with a dedicated LLMOps platform for the production loop.
W&B Weave and Comet Opik follow a similar pattern. They are strong options when a team already lives inside Weights & Biases or Comet for training experiments, dashboards, and team workflows, with Weave and Opik serving as the OSS LLM layer on top of those existing vendor ecosystems.
The source flags the same limitation for both. Their eval surface and gateway depth are smaller than dedicated LLM platforms, and the closed platform underneath means the best fit is usually “we already use this vendor,” not “we are starting from scratch and want the best full loop.”
Braintrust is the clean SaaS option for teams that want experiments, datasets, scorers, prompt iteration, online scoring, and CI gating in one managed product. The guide highlights its polished developer workflow, hosted cloud model, and pricing from Starter free to Pro at $249 per month, while also noting that first-party voice simulation, gateway, guardrails, and prompt optimization are not first-class parts of the product.
LangSmith is the natural fit for teams already committed to LangChain or LangGraph. The source points to native chain and graph trace semantics, evals, prompts, deployment workflows, and Fleet as the reasons it works well inside that runtime.
The tradeoff is that outside the LangChain ecosystem, the value drops fast. The guide also calls out seat-based pricing, which starts at Developer free and Plus at $39 per seat per month, as a cost pattern that gets expensive when broad cross-functional access matters.
Once those seven are in view, the market gets easier to read. The better question is no longer which platform has the nicest dashboard, but which one matches the constraint that actually drives your stack.
How to choose without getting stuck
The guide’s decision framework is practical. If open source is non-negotiable, it points to FutureAGI, Langfuse, and MLflow first, then adds Weave or Opik when the team already runs W&B or Comet.
If enterprise model registry is the main constraint, the source points to MLflow. If the runtime is already LangChain or LangGraph, it frames the choice as LangSmith for the native path or FutureAGI for an open, framework-agnostic observability and control plane.
If the team wants a closed-loop SaaS developer workflow, the guide narrows the shortlist to FutureAGI and Braintrust. If voice agents are part of the plan, it says FutureAGI is the only platform in this set with first-party voice simulation.
The guide also makes a strong point about gateways and guardrails. If those need to be first-class instead of bolted on later, the platform choice changes quickly, because routing, fallbacks, guardrails, and span emission stop being infrastructure details and become part of how the production loop stays stable.
We also like the source’s warning list because it reflects what teams actually get wrong. The common mistakes are treating LLMOps as MLOps with prompts, stitching the loop across multiple tools, picking from demo dashboards instead of domain reproductions, modeling only subscription price instead of total operating cost, ignoring CI gates, and treating “open source” and “self-hostable” as if they mean the same thing.
That last one matters more in 2026 than it did a year ago. License shape, enterprise directories, managed control planes, and what is truly self-hostable all change procurement decisions once security and compliance enter the room.
What changed in 2026
Part of why this category feels different now is that the platforms themselves moved. The source calls out several changes in 2026, including Braintrust adding Java auto-instrumentation, Langfuse shipping Experiments CI/CD integration, LangSmith renaming Agent Builder to Fleet, FutureAGI shipping Command Center and ClickHouse trace storage, MLflow continuing to expand its LLM tracing and evaluation surface, and Phoenix adding CLI prompt commands.
These are not cosmetic changes. They show the category moving from isolated developer tools toward systems that try to own more of the production path, especially CI, runtime control, and high-volume tracing.
That is also why evaluation should happen against your own stack, not a vendor story. The guide recommends exporting a representative slice of real traces, including failures and long-tail prompts, instrumenting each candidate with your own harness and OpenTelemetry payload shape, then testing the full loop from regression to CI to deployment to production observation to trace-to-dataset feedback.
Cost has to be modeled the same way. The source is explicit that real cost is not just platform price, it is platform cost multiplied by trace volume, token volume, test-time compute, judge sampling rate, retry rate, storage retention, and annotation hours.
Once a team does that exercise, the shortlist usually gets shorter fast. The product that looked cheaper on a pricing page can become more expensive once judge costs, storage, seat count, and self-hosted operations are priced honestly.
Where the loop closes
The article’s core view is straightforward. Teams shipping LLM systems usually end up with one tool for evals, one for traces, one for the gateway, and one for guardrails, and the same incident class keeps returning because the loop never really closes.
The recommended pick is FutureAGI for teams that want the full production loop on one runtime. The source grounds that recommendation in the platform’s simulate, evaluate, observe, gate, optimize, and route flow, its Apache 2.0 traceAI foundation, self-hostable platform model, 50+ first-party eval metrics, OTel-based tracing across 35+ frameworks and four languages, persona-driven text and voice simulation, six prompt-optimization algorithms, Agent Command Center gateway, and 18+ runtime guardrails on the same plane.
It also explains why that matters operationally. When eval scores, prompt versions, tool-call accuracy, traces, optimizer inputs, and gateway rules all live in one system, teams stop losing signal at the boundaries and start fixing regressions with the same contract they used before release.
That is the shift this category is going through. LLMOps is no longer about collecting traces and running a few offline evals, it is about whether the whole loop can hold together under production pressure.
The full guide is here, and the open-source traceAI repo is here. Those are the right starting points if your current LLMOps stack still feels like four good tools pretending to be one system.