
Compare Voice AI Evaluation: Vapi vs Future AGI


When building a voice AI agent, it’s not enough that it simply works. It needs to understand context, sound natural, and stay consistent across every interaction. That’s where voice AI evaluation comes in, measuring how well your AI performs in real conversations, not just scripted demos.
In this white paper, we’ll compare Vapi Evals and Future AGI Evals, two leading approaches to voice agent testing and optimization. While Vapi Evals are great for quick, transcript-level checks within the Vapi ecosystem, Future AGI Evals go deeper, simulating real conversations, analyzing tone and naturalness, and providing comprehensive AI agent benchmarking across multiple providers.
1. What Is Voice AI Evaluation and Why Do You Need It?
First impressions matter in voice AI. Users judge an agent within seconds, not by its intelligence, but by how natural it feels. That’s where voice evaluation becomes critical. It’s not just about accuracy; it’s about the entire user experience.
Here’s what can go wrong without proper testing:
The Password Reset Disaster A fintech company deployed a voice assistant for password resets and transaction verification. In real-world use, it consistently misunderstood account details, especially from users with accents or those calling from noisy environments.
The result? Locked accounts, manual interventions, and a surge in complaints.
The root cause: Testing ignored accent diversity, background noise, and audio quality variations.
The Empathy Problem A healthcare provider created an AI nurse for appointment reminders and patient check-ins. Every fact it shared was accurate, but patients hung up quickly. The tone was mechanical and distant.
Text-based metrics showed nothing wrong, but voice analysis revealed the real issue: zero emotional connection.
The root cause: Testing measured correctness, not conversational warmth.
The Silent Update Break A customer service bot worked perfectly until a routine model update broke it. Users suddenly found themselves cut off mid-sentence. The conversation logic was unchanged, only the underlying AI model had been updated.
Without automated checks after the update, the problem went live. Hundreds of failed calls later, the team discovered a timing issue in how responses were generated.
The root cause: No continuous testing after system changes.
Proper evaluation would have caught the timing regression immediately.
At Future AGI, evals aren’t just about assigning a score, they uncover why an agent behaves the way it does. By combining transcript-level and audio-native analysis, Future AGI helps teams pinpoint which stage of the pipeline (STT, LLM, or TTS) caused a performance drop, compare providers side-by-side, and continuously improve agent quality across every interaction.
Why Voice Evals Are Becoming Critical
As voice AI moves from demos to production, expectations have shifted from it works to it works reliably. Three big changes are driving this:
Scale: With thousands of live agents, systematic testing is the only way to catch failures, from poor accent handling to inappropriate tone.
Complexity: Modern systems combine multiple technologies. Evaluation provides objective comparison of different combinations for clarity, intelligence, and naturalness.
Trust: Continuous testing catches problems, degraded quality, tonal errors, logical failures, before users encounter them.
In short, Voice Evals have become the quality backbone of modern voice AI.
Voice Evals turn these blind spots into measurable data, letting teams test for real-world variation before it costs them user trust or brand credibility. Now that we’ve seen why evaluations are essential, let’s look at how today’s leading platforms — Vapi and Future AGI, approach them differently.
2. Understanding Vapi: The Voice Infrastructure Layer
Vapi is a platform built for real-time voice AI. It handles the orchestration of STT (speech-to-text), LLM reasoning, TTS (text-to-speech), and telephony integration, letting you focus on conversation design rather than infrastructure.
In short, Vapi powers the call, managing connections, audio streams, and integrations seamlessly.
Recently, Vapi introduced Vapi Evals, a simple way for developers to test how their agent performs in a simulated or real voice interaction. Vapi generates transcripts and call recordings and provides call-analysis/eval features for transcript-level checks and quick debugging inside the Vapi dashboard, great for validating call flows and short scenarios, but focused primarily on transcript and call-level insights rather than large-scale audio simulation or cross-provider benchmarks.
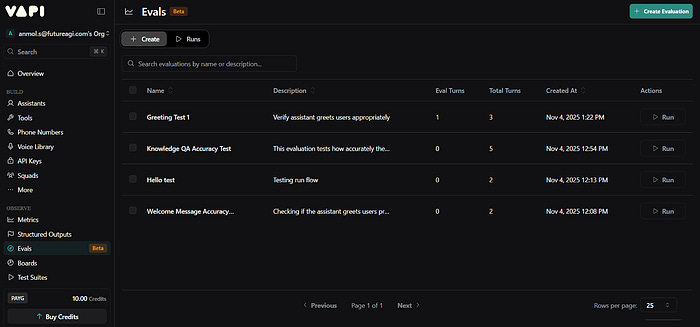
Vapi’s evals provide quick transcript-level checks. However, they evaluate mainly what was said, not how it sounded. There’s no deep analysis of tone, naturalness, or expressiveness.
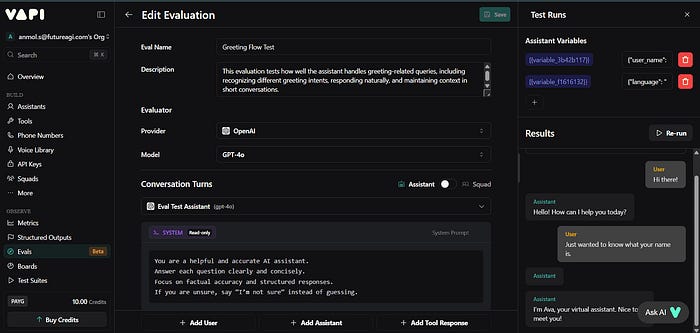
Vapi is excellent for real-time call orchestration, it runs the pipelines that make voice agents possible. Its new evals feature helps developers check basic conversational accuracy, but it remains limited to transcript-level scoring. For deeper analysis, simulation, or cross-provider comparison, you’ll need a dedicated evaluation platform like Future AGI.
3. Understanding Future AGI: The AI Engineering and Optimization Platform
Future AGI is an end-to-end platform for simulation, evaluation, observability, and reliability protection in AI agents. It’s built around one central idea — great AI agents are powered by great evaluations. Instead of handling calls, Future AGI connects to your existing providers like Vapi, Retell, or your own agent through a simple API key.
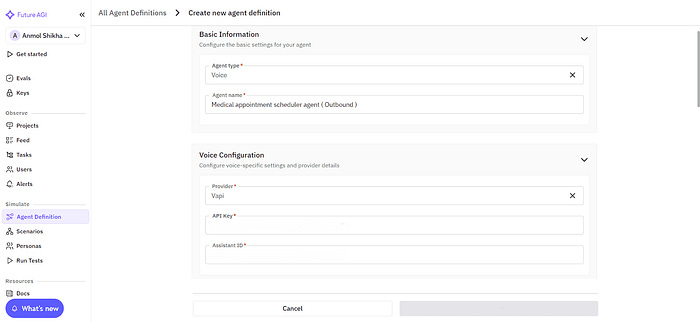
Once connected, it continuously collects evaluation data, simulates conversations, and surfaces insights that help you improve reliability and user experience.
Think of the relationship this way:
Vapi runs the conversation.
Future AGI measures and improves its quality.
After connecting your agent, Future AGI automatically captures detailed performance data across recognition, reasoning, and speech stages. Every conversation is logged with transcripts, audio, and quality metrics so you can evaluate accuracy, grounding, and naturalness in one dashboard.
You can simulate thousands of conversations, evaluate audio quality and coherence, and track real-world performance through a unified analytics view. Each agent has its own workspace where teams can replay interactions, inspect reasoning flow, and spot exactly where quality dropped.
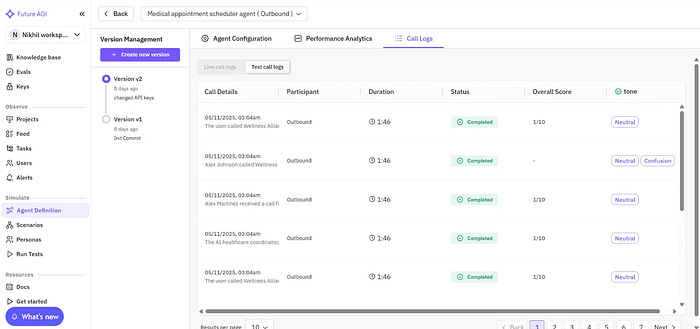
This level of depth helps teams move beyond surface-level monitoring to data and eval-driven refinement, using real interactions to run targeted evaluations, fine-tune prompts, or improve voice performance with precision.
4. Future AGI Evals: What Makes Them Different
Future AGI is more than a testing tool, it’s a full end-to-end platform where evaluation is the core engine that powers simulation, observability, regression protection, and continuous improvement. Rather than treating evals as an add-on, Future AGI embeds them into every phase of the lifecycle so teams can simulate realistic conversations, run audio-native tests, detect regressions automatically, and instrument production with meaningful signals.

Below we explain the platform capabilities that flow from this architecture and why treating evals as the engine changes how teams build and operate voice agents.
4.1 Simulation-Driven Evaluation
Traditional evals depend on live calls, which makes large-scale testing slow and expensive.
Future AGI replaces that with simulation-based evals, allowing you to recreate thousands of realistic voice interactions, accents, background noise, interruptions, emotion shifts, or off-script turns, without consuming real call minutes. Simulated audio-native runs are designed to avoid consuming production telephony minutes and enable statistically significant sampling.
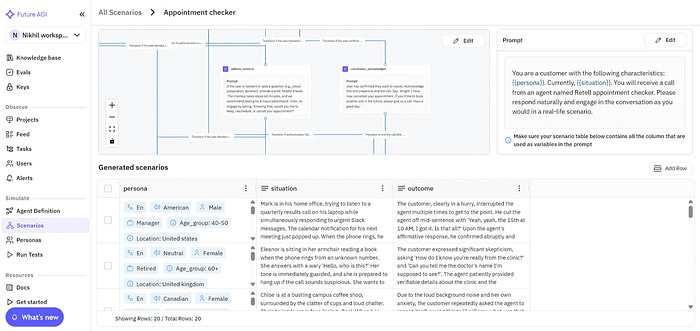
These audio-native simulations let you measure voice quality and conversational stability in a controlled, repeatable environment. Teams get statistically reliable insights that mirror real-world performance, before agents ever go live.
The interface below shows how teams select and configure voice scenarios for large-scale simulation.
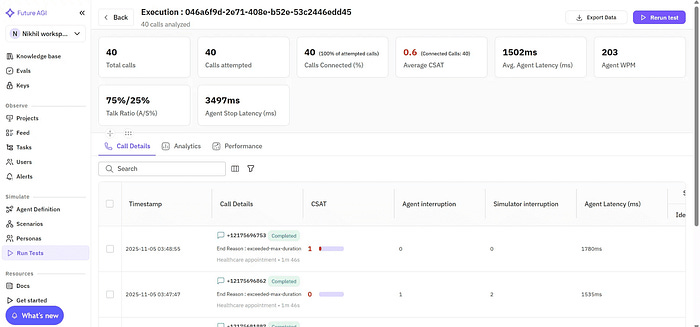
After simulation runs, Future AGI provides detailed playback and evaluation insights , including recordings, transcripts, and per-eval results, to help teams analyze performance and quality metrics at every turn.
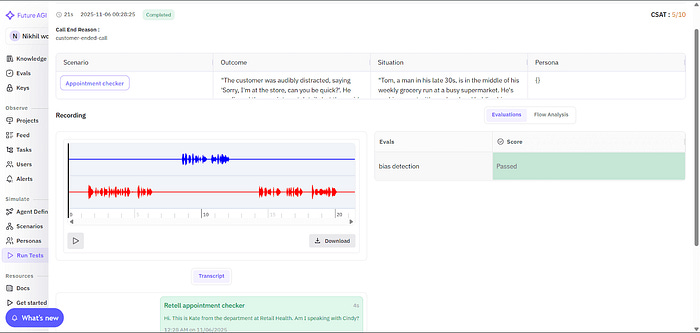
4.2 Benchmarking Voice Models to Find What Works Best for Your Use Case
Future AGI evaluates agents across the entire voice-AI pipeline — from Speech Recognition (STT) to Reasoning (LLM) to Speech Output (TTS), and does so across multiple providers.
With this setup, teams can:
Compare model reasoning performance (GPT-4, Claude, Gemini, etc.) for accuracy, grounding, and coherence.
Identify the optimal STT + LLM + TTS combination for specific use cases.
Benchmark end-to-end performance across Vapi, Retell, or custom stacks through direct API connections.
Examine per-stage metrics that isolate how each component of the pipeline contributes to overall quality.
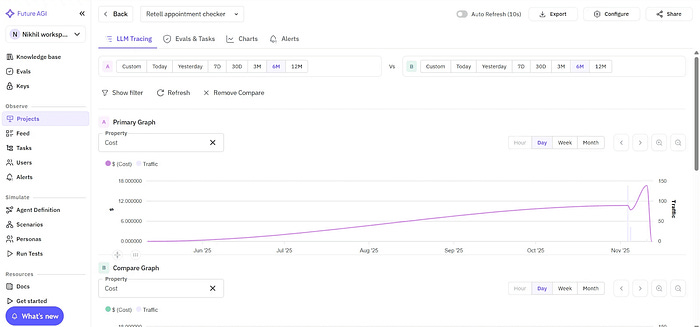
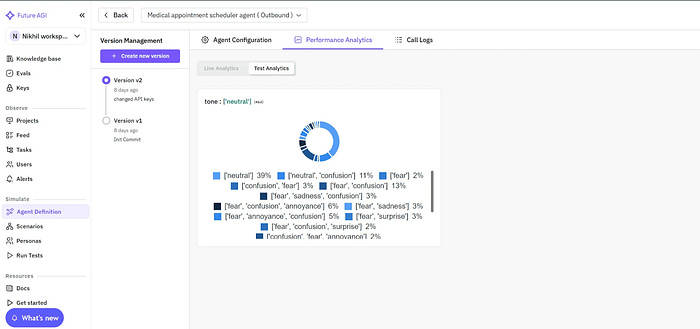
Unlike Vapi Evals, which work only within Vapi, Future AGI delivers cross-provider benchmarking so you can pick the most reliable stack for production.
4.3 Root-Cause-Aware Evaluation
Knowing that something failed isn’t enough; knowing why it failed is what drives improvement.
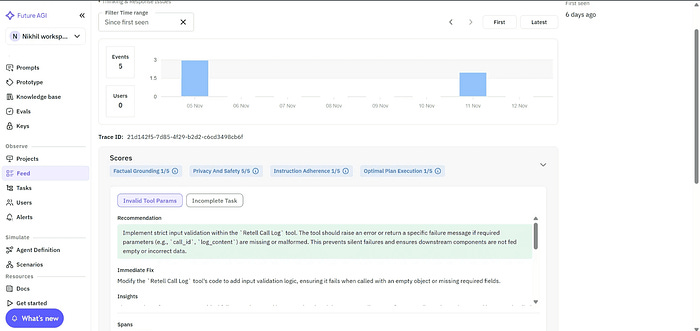
Future AGI’s Agent Compass groups similar failures, highlights the exact turn where the issue occurred, and provides actionable recommendations to pinpoint whether an error arose in STT, reasoning, or speech synthesis.
4.4 Continuous Evaluation Integrated into Your CI/CD Pipeline
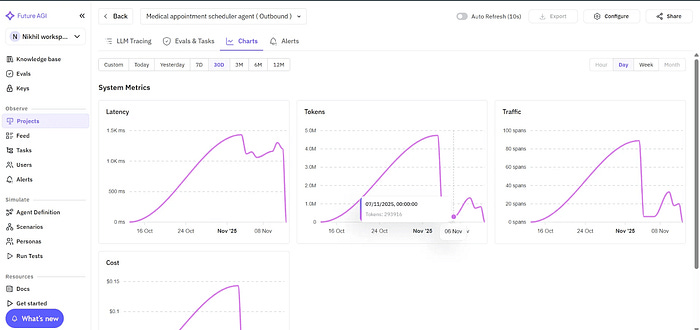
Every time your team updates a prompt, swaps an LLM, or adjusts TTS parameters, Future AGI integrates directly with your CI/CD pipelines. It supports both scheduled and automated test runs, allowing teams to replay evaluation sets after each update and catch regressions before they reach production. This ensures that every model, prompt, or voice change maintains consistent reliability over time.
Pros
Simulation-first approach that replaces manual QA with scalable, audio-native testing
Cross-provider benchmarking for objective quality comparison across Vapi, Retell, and custom pipelines
Root-cause insights through Agent Compass that show exactly what went wrong and why
Continuous regression detection that safeguards performance over time
Comprehensive metrics covering clarity, tone, naturalness, and conversational stability
Cost-efficient at scale, since no live call minutes are consumed
Cons
Slightly steeper learning curve for non-technical users at setup.
Best suited for teams ready to do series testing rather than one-off checks.
In short, Future AGI Evals transform evaluation from a checkbox task into a continuous improvement cycle. They don’t just tell you whether your agent works, they explain how well it performs, why it behaves that way, and what to fix next so every conversation sounds consistent, confident, and human.
Now that we’ve seen how both eval systems work, here’s a quick side-by-side look at how they compare across key areas.
Conclusion
Vapi handles live voice calls with low latency and strong reliability. It’s the runtime platform that powers real-time voice conversations.
Future AGI is the testing and optimization platform that evaluates agent performance before deployment.
When voice AI drives critical operations, support, sales, healthcare, you need scalable evaluation.
Future AGI lets you:
Test at scale: Run thousands of conversation scenarios quickly
Catch issues instantly: Detect quality drops after any update
Diagnose precisely: Pinpoint exactly where performance declined
These aren’t competing tools, they serve different stages. Vapi runs live conversations; Future AGI ensures they stay high-quality.
As you scale, evaluation becomes essential. Future AGI helps you test, simulate, and optimize before users are affected.
👉 Read our docs or book a demo to see it in action.