
AI Model Benchmarking: A Technical Guide for Developers in 2025
AI Model Benchmarking: A Technical Guide for Developers in 2025


1. Introduction
Selecting the right AI model from hundreds of options claiming superior performance is challenging. Without rigorous evaluation frameworks, developers risk investing time in models that underperform in production environments. Benchmarking provides the empirical foundation needed for informed decision-making.
Large Language Models have evolved significantly throughout 2025. Google released Gemini 2.5 Pro in March 2025 with enhanced reasoning capabilities and a one million-token context window. OpenAI refined GPT-4o’s multimodal processing, achieving 320-millisecond response times across text, audio, and visual inputs.
2. Why Benchmarking Matters for Developers
Model selection directly impacts project outcomes, user satisfaction, and development costs. Benchmarking provides three critical advantages:
Reliability verification: Benchmarks confirm whether models consistently deliver accurate, relevant, and safe outputs across diverse scenarios.
Objective comparison: Standardized testing conditions enable fair model comparisons, revealing which performs best for specific requirements.
Development optimization: Benchmarks track training progress and signal when models are production-ready.
This analysis examines Claude 4, Claude Sonnet 3.7, Grok-3, Grok-4, GPT-5, and Gemini 2.5 across multiple dimensions to guide model selection in 2025.
Top AI Models: Deep Dive
3.1 OpenAI (GPT-4o, o3, GPT-5)
OpenAI focuses on building versatile, general-purpose AI systems. GPT-5’s 2025 release advanced their generalist approach, excelling across domains without extensive customization. The expanded multimodal processing now includes native video understanding, demonstrating capability across input types while maintaining generalist strength.
Core Architectural Elements:
Advanced multimodal system: GPT-5 processes text, images, audio, and video in unified architecture
Extended context windows: GPT-5 offers 256,000 tokens; GPT-4o maintains 128,000 tokens
Iterative improvement philosophy: Continuous refinement based on real-world feedback
Native multimodal features: Built-in capabilities eliminate external tool requirements
Optimized inference: GPT-5 balances reasoning depth with speed, achieving 200ms latency
Enhanced safety measures: Constitutional AI principles integrated into GPT-5’s training
3.2 Google (Gemini 2.5)
Gemini 2.5 was engineered for deep reasoning through native multimodal intelligence. The architecture processes text, images, audio, and video cohesively rather than as separate inputs, enabling consistent reasoning across data types.
Core Architectural Elements:
Native handling for text, audio, images, video, and code libraries
Deep Think mode evaluating multiple options before responding
1 million token context window accommodating entire codebases
Configurable thinking budget controls for reasoning depth
Enhanced security reducing prompt injection risks by approximately 40%
3.3 Anthropic (Claude 4, Sonnet 3.7)
Anthropic’s Constitutional AI approach emphasizes transparent reasoning and safety through alignment-focused training. Claude 4’s dual-mode architecture switches between rapid responses and deep analysis, addressing both conversational and complex analytical needs. The emphasis on enterprise-grade safety and strong coding capabilities makes Claude suitable for teams requiring interpretable AI.
Core Architectural Elements:
Dual-mode thinking shifting between rapid and in-depth processing
Constitutional AI framework ensuring transparent, secure responses
Memory architecture supporting large-scale enterprise tasks
Superior coding performance: 72.5% on SWE-bench Verified
Agent-ready infrastructure for autonomous planning and execution
3.4 xAI (Grok-3, Grok-4)
xAI pioneered multi-agent architecture where discrete AI components collaborate to solve complex problems. Grok 4 leverages significant computational resources for real-time reasoning, running on the Colossus supercomputer with over 200,000 NVIDIA H100 GPUs. Live data integration and mathematical emphasis support scenarios requiring current information and deep analysis.
Core Architectural Elements:
Multi-agent collaboration with discrete AI components working in concert
1.7 trillion parameters trained with 100x compute of predecessors
Live data connections providing real-time information access
Mixture of Experts transformer architecture improving computational efficiency
Novel reinforcement learning approach extending beyond next-token prediction
These architectural approaches reflect distinct priorities: OpenAI emphasizes broad utility, Google focuses on seamless multimodal understanding, Anthropic prioritizes transparent reasoning and safety, and xAI pushes boundaries with scale and real-time capabilities.
4. Comparative Performance Analysis
4.1 Reasoning and Intelligence
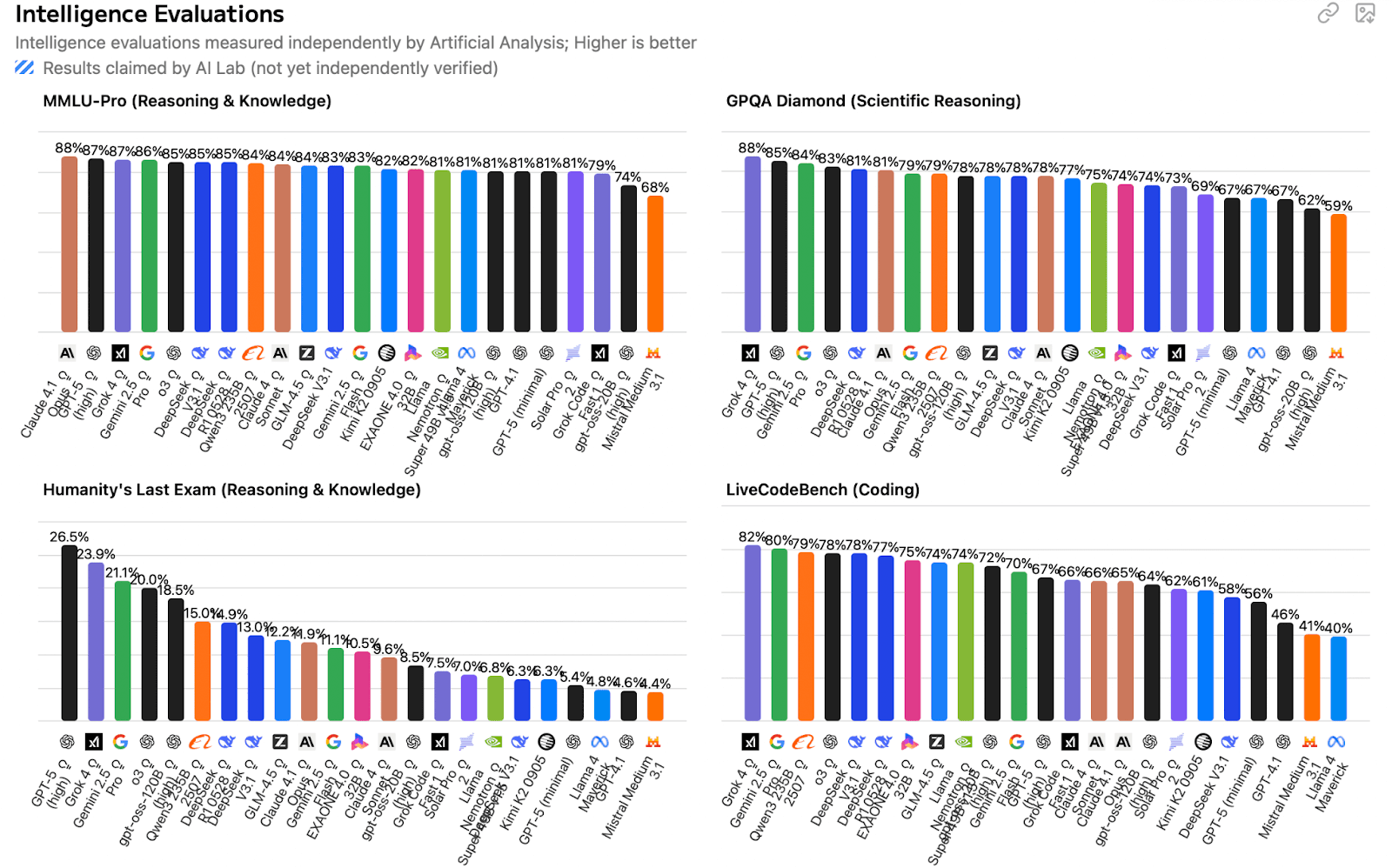
Grok-4 leads in complex reasoning tasks with results pushing current AI capabilities. Gemini 2.5 Pro demonstrates strong adaptive reasoning, while GPT-5 delivers reliable performance across cognitive challenges. These outcomes matter for applications like deep analysis, scientific problems, or abstract reasoning where errors are costly.
Key Benchmark Results:
Grok-4: 87.5% on GPQA Diamond (graduate-level scientific reasoning)
Gemini 2.5 Pro: 84.0% on GPQA Diamond, plus 18.8% on Humanity’s Last Exam
GPT-5: 83.3% on GPQA Diamond (consistent general reasoning)
Claude 4 Sonnet: 75.4% on GPQA Diamond with extended thinking; 70.0% without
Grok-4 Heavy: 100% on AIME 2025 (mathematical reasoning benchmark)
4.2 Coding and Software Engineering
Grok-4 and GPT-5 lead in autonomous coding performance. Grok-4’s specialized architecture excels at complex, independent coding tasks, while GPT-5 provides versatile performance. Claude models dominate code analysis and documentation. Performance variations indicate each model family has distinct strengths.
Software Engineering Performance:
Grok-4: 75% on SWE-bench (autonomous coding, complex debugging)
GPT-5: 74.9% on SWE-bench Verified (complex logic, algorithm implementation, multi-file management)
Claude 4 Sonnet: 72.5% on SWE-bench Verified (excellent documentation and explanations)
Claude 3.7 Sonnet: 70.3% with custom scaffold (standard development tasks)
Gemini 2.5 Pro: 67.2% on SWE-bench Verified (large codebase management)
OpenAI o3: 71.7% on SWE-bench Verified (competitive programming)
4.3 Context Window and Data Processing
Context window size determines whether models handle enterprise-scale tasks or more focused operations. Gemini 2.5 Pro’s extensive window enables analysis of complete research papers or entire codebases, while others target specific scenarios. These constraints significantly impact performance in data-intensive environments.
Context and Scale Capabilities:
Gemini 2.5 Pro: 1 million token capacity for comprehensive research
GPT-5: 400,000 token window (272,000 input / 128,000 output) for advanced applications like detailed codebase analysis and multi-document synthesis
Claude 4: 1 million token window for technical document analysis
GPT-3 (o3): 200,000 token capacity for general use
Grok-4: 1.7 trillion parameters with 256k token window
Processing Impact: Large context windows enable whole-codebase analysis, academic paper review, and multi-document synthesis tasks.
4.4 Speed and Latency
Response speed determines suitability for real-time applications. Gemini’s Flash versions deliver fastest output rates, while others balance speed with reasoning quality. These differences determine optimal use cases: real-time interactive applications versus batch processing where accuracy outweighs speed.
Speed Performance Metrics:
Gemini 2.5 Flash-Lite: 275 tokens/second (real-time applications)
GPT-5 nano: 122.8 tokens/second (high-frequency, latency-critical tasks)
GPT-5 (high): 65.5 tokens/second (complex analysis prioritizing quality)
GPT-4.1: ~128 tokens/second (balanced speed and reasoning)
Grok-3: 63 tokens/second (prompt responses)
Claude 4 Sonnet: ~2x faster than Claude 3.7 while maintaining quality
Latency Trade-offs: Faster models enable live chat applications; slower models provide deeper reasoning.
4.5 Cost Efficiency
Pricing structures reveal significant deployment cost variations, with Gemini 2.5 Pro offering most competitive rates for high-volume applications. Cost considerations become critical at scale as token usage rapidly accumulates. Understanding these metrics enables smart budget planning across use cases.
Pricing Comparison:
Gemini 2.5 Pro: $1.25/$10 per million tokens (input/output) — highly affordable for enterprise
GPT-5: $1.25/$10 per million tokens with cheaper variants:
GPT-5 mini: $0.25/$2.00 per million tokens
GPT-5 nano: $0.05/$0.40 per million tokens
GPT-4.1: ~$2/$8 per million tokens
Claude 4 Sonnet: $3/$15 per million tokens (premium for superior coding)
Grok-4: $3/$15 per million tokens (doubles after 128k context)
Economic Impact: Price variations significantly affect viability for individual developers versus large-scale enterprise deployments.
Use-Case Specific Recommendations
5.1 Academic and Research Applications
Gemini 2.5 Pro is optimal for academic research due to its 2 million token context window, enabling analysis of complete research papers, dissertations, and comprehensive literature reviews in single passes. Research teams report ~70% time savings using Gemini 2.5 Pro for large dataset analysis and multi-source synthesis. Its 84.0% GPQA Diamond score demonstrates graduate-level scientific reasoning capability, while $1.25/$10 pricing makes it cost-effective for academic budgets.
Key Research Features:
Process multiple academic papers simultaneously without context loss
Accurate citation management with proper source attribution
Statistical analysis support for quantitative research
Literature synthesis capabilities for systematic reviews
GPT-5 Alternative: With 86.0% on GPQA Diamond and 256k context window, GPT-5 excels at complex analytical tasks like hypothesis generation and cross-referencing multiple studies, particularly when multimodal data (images, datasets) is involved.
5.2 Software Development and Engineering
The coding landscape splits between two leaders: Grok-4 for autonomous development tasks and Claude 4 Sonnet for collaborative environments with documentation needs. Grok-4’s 75% SWE-bench score makes it ideal for independent coding where AI handles complex debugging and feature implementation autonomously. Claude 4 Sonnet’s 72.7% SWE-bench performance combined with exceptional documentation clarity suits teams prioritizing maintainable code and knowledge sharing.
Development Workflow Optimization:
Grok-4: Excels at greenfield projects and complex algorithm implementation
Claude 4 Sonnet: Superior code reviews and technical documentation
Both: Strong multi-file refactoring and integration testing across frameworks
5.3 SEO and Content Generation
Content creation requires balancing technical optimization with human engagement. Claude 4 leads for meaningful content that serves both search engines and readers. Constitutional AI training produces naturally flowing content with seamless keyword integration avoiding forced or artificial phrasing.
GPT-3 (o3) provides strong backup for high-volume content generation, offering varied outputs avoiding repetitive patterns across large collections. GPT-5 advances this with superior natural language generation, delivering creative, human-like outputs excelling in long-form content while seamlessly incorporating semantic search optimization.
Content Creation Strengths:
Natural keyword integration without forced phrasing
Compelling meta descriptions improving click-through rates
Topic cluster and pillar content development
Consistent brand voice across content formats
5.4 Real-Time Data and Market Analysis
Grok-3 distinguishes itself with native live data stream access, making it unmatched for tracking market movements and real-time social media monitoring. Unlike models limited to training cutoff data, Grok-3 pulls fresh information from X (formerly Twitter) to identify emerging trends, track sentiment shifts, and capture breaking developments impacting markets. This real-time access is transformative for traders, marketers, and analysts requiring immediate public sentiment and trending topic awareness.
Real-Time Analysis Capabilities:
Emerging keyword detection minutes after trending begins
Cross-platform sentiment analysis
Market sentiment tracking for investment decisions
Crisis monitoring and brand reputation management
Each recommendation reflects the practical reality that no single model dominates every use case.
Conclusion
Selecting an AI model should prioritize workflow alignment over maximum benchmark scores. Advanced teams already employ multi-model strategies leveraging each AI family’s strengths, creating adaptable stacks that adjust to different project phases.
Current benchmarks approach saturation with many models achieving near-perfect scores, making differentiation through traditional metrics increasingly difficult. The future lies in dynamic evaluation systems adapting to emerging capabilities and providing businesses with custom metrics aligned to their objectives. Future AGI evaluation modules will enable developers to create custom benchmarking frameworks measuring what matters for their specific applications, moving beyond one-size-fits-all scoring systems that fail to capture real-world performance differences.
FAQs
Which AI model should I choose for my software development team?
For autonomous coding work, go with Grok-4 thanks to its strong 75% score on SWE-bench, or pick Claude 4 Sonnet if you need great team collaboration and clear documentation, where it hits 72.7% on SWE-bench with top-notch explanations.
What’s the most cost-effective AI model for high-volume applications?
Gemini 2.5 Pro gives you the best bang for your buck at $1.25/$10 per million tokens, plus its huge 2 million token context window makes it perfect for crunching through big datasets and research tasks.
Which model performs best for mathematical and scientific reasoning?
Grok-4 is the standout here, scoring 87.5% on GPQA Diamond and nailing a perfect 100% on AIME 2025, so it’s your go-to for serious research and math-heavy projects.
How do I handle real-time data analysis and market monitoring?
Grok-3 is built for this with its seamless tie-in to live social media feeds, letting you spot trends and analyze sentiments right away in a way that others can’t touch since they’re stuck with outdated training data.
What’s your experience with these AI models? Which benchmarks matter most for your use case? Share your thoughts in the comments.